Appearance
参考
这可能是最通俗的 React Fiber 打开方式,这篇文章写得太稳了
https://www.youtube.com/watch?v=ZCuYPiUIONs 视频 A Cartoon Intro to Fiber – React Conf 2017 强烈推荐
React设计思想
https://www.kancloud.cn/kancloud/react-in-depth/47779 这篇文章写得很好,但是好像没有更新了
React设计有几个核心的点
createElement
通过JSX编写富有表达力的声明式UI代码,JSX只是一种用于创组件的XML语法,最终是通过JavaScript对象对应的虚拟DOM来描述真实DOM节点
借助虚拟DOM,可以实现component、props、children、onEvent等多种技术层面的封装,从而构建大型Web应用
整体刷新
如果由每个组件自己去维护自己的数据状态和UI更新,工作量无疑是很庞大的,不如每次都从整体来刷新UI。这听上去可能有性能问题,但我们有虚拟DOM,可以通过diff算法来极大地提高性能
diff算法目的是对比新旧节点列表,尽可能地减少操作DOM(创建、更新、移动、删除)的步骤,比较有代表性的实现包括snabbdom、infernoJS等
递归diff
既然是整体刷新,意味着每轮更新都需要从根节点开始遍历diff新旧节点,遍历树最简单的方式就是递归。递归的优势是逻辑清晰,实现简单
循环diff
递归的问题在于无法临时中断,这导致开始递归之后就必须等待它执行完毕,如果时间过长,则会导致浏览器无法响应用户的交互。
因此React16引入了Fiber的概念,它的主要作用是将无法中断的递归diff改成可以临时中断的循环diff,给浏览器留够可以交互的时间,让页面看起来不卡顿。
Fiber是本文关注的目标点。
Fiber:协程
Fiber 也称协程、或者纤程。协程跟线程还不太一样,跟进程就更不一样了。首先明确,协程只是一种控制流程的让出机制。
普通函数的执行无法被中断,如果要递归遍历完整个树,就需要等到他执行完毕
js
function walk(root){
if(!root) return
// ...一些耗时操作
walk(root.left)
walk(root.right)
}但ES6之后,情况发生了变化,我们可以使用Generator了
js
function* walk(root) {
if (!root) return;
// ...一些耗时操作
yield* walk(root.left);
yield* walk(root.right);
}
const w = walk(root);
console.log(w.next());
// 可以做点事情
console.log(w.next());
// 可以做点事情
console.log(w.next());
// 可以做点事情
console.log(w.next());浏览器在一帧中要干很多事情,执行JavaScript代码只是一小部分任务,如果占用时间过多,就会导致页面卡顿

假设每次walk的耗时操作需要执行10ms,一共执行5次,
- 在递归模式下,整个程序会占用50ms
- 在Generator下,每10ms之后,控制权归还给代码,至于何时调用next,则由代码控制
这个过程蕴含了这个”协“字的真正含义:互相信任,相互协作
- 浏览器信任函数,每次只执行10ms
- 函数信任浏览器,每隔一段时间就继续调用函数
这就是React Fiber的核心思想:React diff过程可以被中断,将控制权交回浏览器(浏览器可以执行高优先级的任务避免页面卡顿),等待浏览器空闲后再恢复diff。
看起来挺简单的,上面的短代码用Generator就可以实现了,那React为什么没有采用呢?来看看这个回答
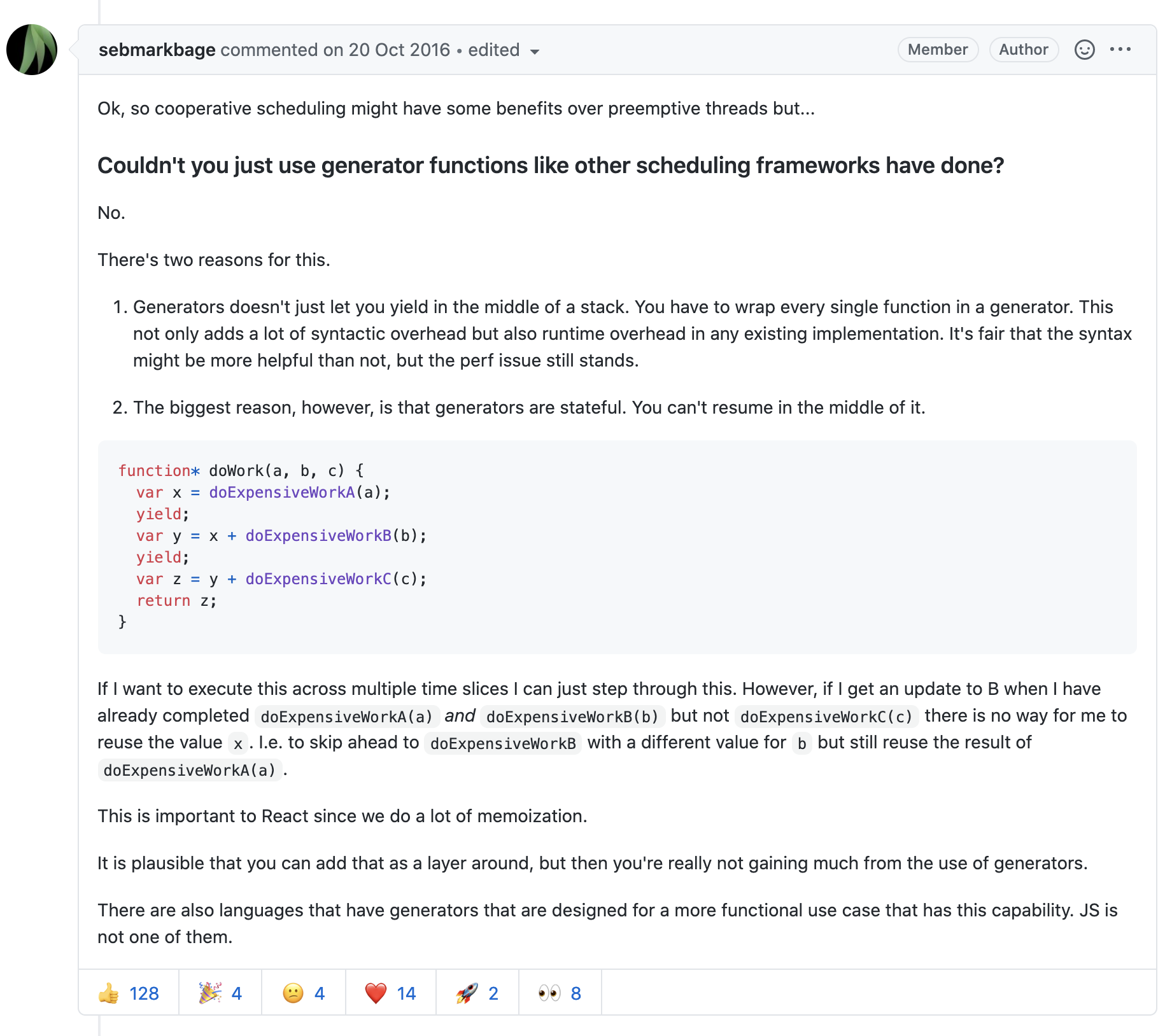
简单来说就是Generator不能在栈调用的时候让出,除非把所有的嵌套函数都改成Generator,加上无法复用和恢复某些状态,以及额外的语法开销等问题。最终,React决定自己搞一个协程。
根据协程的信任机制,我们相信浏览器在空闲的时候会执行diff,我们也自觉的在执行一段时间后将控制权交给浏览器。
对于第一个点,浏览器甚至提供了一个API,让我们注册在浏览器空闲的时候需要做的事情
js
window.requestIdleCallback(() => {
console.log("做点啥");
});当然在requestIdleCallback中要保持自觉,虽然能做,但只能做一点点。那一点点是多久呢?来个经验值吧,5ms看起来还可以。
对于第二个点,就需要我们在5ms过后归还控制权,可以在完成单个最小工作单元(比如diff一个节点)之后,就可以检测有没有时间剩余,如果没有剩余时间,就暂停了嘛。
调度器
在协程的思路下,需要有一个调度器来负责什么时候执行diff任务,什么时候归还控制权执行其他高优先级交互任务。
其核心思想很简单:在浏览器空闲的时候做点diff任务,没时间了就归还控制权
js
window.requestIdleCallback(() => {
console.log("做点啥");
});在浏览器每次空闲的时候做点事情
js
const performWork = () => {
window.requestIdleCallback(() => {
console.log("做点啥");
// 时间不够了,下次有空了继续来
performWork()
});
};
performWork()基于这个思路,我们可以实现一个简版的调度器
js
const frame = 1000 / 60;
const queue = []
let deadline = 0;
const getTime = () => +new Date()
const shouldYield = () => getTime() >= deadline;
const schedule = (cb) => window.requestIdleCallback(cb);
// 按顺序执行queue
const flushWork = () => {
deadline = getTime() + frame
const task = queue.shift()
while (task && !shouldYield()) {
task()
}
// 还有任务未执行完,则等待下一次的调度
if (queue.length) {
schedule(flushWork)
}
}
const scheduleWork = (task) => {
queue.push(task)
schedule(flushWork)
};调度器更像是一个无情的工作机器,有任务了就安排在合适的实际执行。然而真正的难点不在于执行任务本身,而在于状态控制。
循环暂停期间的状态控制
假设现在有1到10这个10个节点,理想状态下,整个工作流程按照 开始-暂停-继续-暂停-...-完成就结束了,大家都相安无事。
第一个问题:那么我们可以先更新已经执行完成的节点的DOM吗?
答案是不行,更新DOM节点就意味着用户能看见页面的更新,在任务未全部执行完之前就更新DOM,用户在某些时刻会看见部分新UI部分旧UI同时存在,以及页面闪烁等问题。
解决办法是:在diff的阶段只负责收集每个节点的变化,最后再同步将所有变化统一更新到DOM上。这个过程类似于git开发,在开发的时候可以随时git add 一些变化(如添加、更新、删除等)进去,最后统一进行git commit
第二个问题:假设在第一次空闲时间我们执行到了第3个节点,在交出控制权后的这段时间用户点击了一个按钮(或者是其他一些奇奇怪怪的操作),影响了第1个节点的状态,那是不是意味着我们需要从头重新计算呢?
状态的准确性决定了最后DOM状态的统一,在这种情况下,肯定需要从头计算。
随之而来的第三个问题:从头计算会不会造成性能浪费,之前已经完成工作的那一部分都白费了?
以至于第四个问题:如果每次在未执行完所有任务前,都由于新触发的状态更新导致重头计算,那是不是永远无法完成所有任务了?
在同步递归diff的时候不会存在这些问题,用户的交互始终都会在所有状态更新之后才会重新修改状态(当然每次更新状态都重新触发diff也是不明智的,因此有nextTick等方式合并状态更新。
而在异步执行diff任务时,必须要考虑这些问题,这些问题导致整个实现非常复杂。
什么时候从头重新执行
在调度器重新调用执行任务前,都会去判断是否有更高优先级的任务插进来,如果有,不好意思,打断循环,重新开始
任务的优先级怎么定义呢?
更新原因的不同,导致他们的优先级不同, https://segmentfault.com/a/1190000038947307
事件优先级,不同的事件对应不同优先级
更新优先级,根据事件优先级计算更新优先级
任务优先级,上面提到的循环任务,存在前比后低,直接取消前;前等于后,复用前者;前比后高,先执行前,再对后重新执行一次调度
调度优先级
双缓冲:状态复用
由于已经访问过的节点还有可能被从头访问,因此,在单次访问期间,不能直接修改已经变化的节点。
回想一下diff过程,新旧VNode进行对对比,新节点会保存更新后的数据状态,同时在处理新节点时会生成新的子节点,这些已经生成的子节点是不是可以复用一下呢?
所以每个节点需要保存变化前的数据,还需要保存上一次循环时已经处理好的即将变化之后的数据,这样可以保证重新循环时原始的数据不会被污染,也可以在复用上次循环时已经执行的任务
React把新的Vnode叫做WIP(work in progress)
由于每个节点默认都有其变化前的数据,再创建一个备份节点用于保存变化后的数据,最后将旧节点替换成备份节点就可以了吧,这里用到了双缓冲。当然也不是每个备份节点都可以被重复使用。
这个可以理解为git checkout,在分支上进行的所有改动都会不影响master,结合上面的add 和commit,最后在merge到master上,完成整个界面的更新。
双缓冲技术:图形绘制引擎一般会使用双缓冲技术,先将图片绘制到一个缓冲区,再一次性传递给屏幕进行显示,这样可以防止屏幕抖动,优化渲染性能。

最简单的情况
上面提到的这些方法,都是为了解决异步状态同步的问题。
在不考虑性能和始终无法结束的问题,假设React就是简单的每次变化都重新计算,这样看起来就会简单很多。
Fiber:数据结构
了解了上面的需求背景之后,现在来设计一下数据结构
循环遍历树
把VNode树的递归遍历转换成循环遍历,是实现可中断调度的核心。
使用链表就可以实现,每个节点维持对于父节点和下一个兄弟节点的引用,就可以将树的递归修改为链表的遍历
ts
class TreeNode {
val: any
parent: TreeNode // 父节点
child: TreeNode // 第一个子节点
nextSibling: TreeNode // 下一个兄弟节点
constructor(val, parent, child, nextSibling) {
this.val = val
this.parent = parent
this.child = child
this.nextSibling = nextSibling
}
}
function walk(treeNode) {
let current = treeNode
while (current) {
// ...处理单个节点
if (current.child) {
current = current.child
} else if (current.nextSibling) {
current = current.nextSibling
} else {
// 处理父元素的兄弟元素
let next = current.parent
while (next) {
if (next.nextSibling) {
next = next.nextSibling
break
}
next = next.parent
}
current = next
}
}
}
// a
// b c
// d e f
// a -> b -> d -> e -> 重回b -> c -> f -> 重回c -> 重回a在改成链表的循环之后,就可以随时暂停和退出了
接入调度器
调度器提供了一个shouldYield的方法,来控制什么时候退出循环;提供了一个scheduleWork方法,来控制什么时候继续循环
在最简单的情况下,只需要在每次循环时判断一下就可以了
js
let current
function walk(treeNode) {
current = treeNode
while (current) {
if(!shouldYield()){
// 退出循环
scheduleWork(()=>{
walk(current) // 同时通知调度器在合适的时候从当前节点遍历
})
return
}
// ...正常遍历流程
}
}放弃循环重新开始的情况
重置current
alternate
diff过程就是旧树与新树的对比,其中
- 旧树是已经存在的,一般叫做current tree或者old tre
- 新树是从应用根节点开始,使用类组件实例render或者重新运行函数组件