Appearance
先介绍一下工作中最常见的应用层协议:HTTP。
HTTP
参考之前
HTTP:超文本传输协议(英文:HyperText Transfer Protocol,缩写:HTTP)是一种用于分布式、协作式和超媒体信息系统的应用层协议,是万维网(WWW)的数据通信的基础。
报文
HTTP报文是浏览器和服务器之间发送的数据块,是信息的基本单元。
报文的格式和语义由协议规范定义,主要包含三个部分
- 对报文进行描述的起始行
- 包含属性的首部块
- 可选的,包含数据的主体部分
一个简单的请求报文
GET /index.html HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0一个简单的响应报文
HTTP/1.1 200 OK
Content-Type: text/html
Content-Length: 123
<html>
<body>
...
</body>
</html>请求报文和响应报文最主要的结构区别在于起始行不一样:
- 请求报文的首部行包含请求方法,资源URL和HTTP版本号
- 响应报文包含HTTP版本号,请求资源的响应状态(一个三位数)和原因短语(一个英语短语文本)
首部行字段
参考:前端必备HTTP技能之HTTP请求头响应头中常用字段详解
首部行携带了一些关于报文的原始信息,可分为通用首部、请求首部、响应首部、实体首部等,下面列举了一些常见的头部,每个字段又有一些常用的属性值
通用头部字段(既可以出现在请求中,也可以出现在响应中):
Cache-Control: 控制缓存行为,例如no-cache表示不使用缓存。
Connection: 指定与连接相关的属性,如keep-alive表示持久连接。
Date: 表示消息的创建时间。
Pragma: 类似于Cache-Control,用于向后兼容。
请求头部字段:
Host: 指定请求的目标主机和端口号。
User-Agent: 标识客户端的用户代理,通常是浏览器信息。
Accept: 指定客户端能够处理的响应的媒体类型。
Accept-Language: 指定客户端能够处理的响应的自然语言。
Authorization: 包含用于进行身份验证的凭据,通常用于发送用户名和密码。
Cookie: 包含之前服务器通过Set-Cookie头部发送的Cookie信息。
响应头部字段:
Location: 用于重定向,指定新的URI。
Server: 描述服务器信息。
WWW-Authenticate: 表示需要进行身份验证。
Set-Cookie: 用于在响应中向客户端设置Cookie。
实体头部字段(在请求或响应的消息体中使用):
Content-Type: 指定消息体的媒体类型。
Content-Length: 指定消息体的长度。
Content-Encoding: 指定消息体的编码方式,如gzip。
Content-Language: 指定消息体的自然语言。
其他常用头部字段:
Referer: 表示请求的来源,即引用页。
Origin: 表示发起请求的域,用于跨域请求。
DNT (Do Not Track): 表示用户不希望被追踪。
If-Modified-Since: 如果服务器在指定时间后对资源进行了修改,则发送请求。
Upgrade-Insecure-Requests: 表示客户端希望升级为安全连接,用于HTTPS。
常见的请求方法
HTTP最初设定了多种请求方法
GET: 用于请求服务器发送某个资源。客户端通过GET方法向服务器请求特定资源的表示,服务器将资源返回给客户端。
POST: 用于向服务器提交数据,通常用于创建新资源。POST请求可能会导致服务器上的处理,如在数据库中创建新条目。
PUT: 用于向服务器上传数据,通常用于更新已存在的资源。客户端发送的数据包含了资源的新表示。
DELETE: 请求服务器删除指定的资源。
HEAD: 类似于GET,但服务器只返回头部信息,不返回实际的资源。通常用于检查资源的元信息,如是否已经修改。
OPTIONS: 用于获取目标资源所支持的通信选项。客户端可以查询服务器支持的方法、头部或其他信息。
PATCH: 用于对资源进行部分修改。客户端发送包含要应用到资源的部分修改的请求。
TRACE:回显服务器收到的请求,主要用于测试或诊断。
需要认识到的是,HTTP最初设定了多种请求方法,这些方法在本质上没有任何区别,只是让请求更加有语义而已,大部分应用都只使用了GET和POST就完成了应用的搭建。
一个经常遇见的问题是:GET和POST有什么区别?
就日常使用经验来看
- 传递请求数据的方式不同,GET将参数添加在URL的查询字段后(URL位于请求报文的起始行),而POST将请求数据放在请求报文的主体部分
- 由于浏览器可能缓存带有查询字段的URL,因此不能保证安全而被其他访问者查看;POST“相对”而言会安全一点
- 某些浏览器对于URL的长度是有限制的,服务器一般也对URL长度有某些限制(超过会返回414错误),因此在需要向服务器传递大量数据的时候一般使用POST方法
- 貌似部分浏览器和框架对于GET会发送一个TCP包,POST会发送两个包,但并不全是这样,具体可以参考这里,这不是HTTP本身协议的问题。
常见的状态码
状态码是一个三位数,第一位描述状态的一般类别(成功,失败...),后两位描述状态的详细信息
- 1表示信息提示
- 100 Continue 表示服务器已经收到了请求的部分,并且客户端可以继续发送请求的剩余部分。
- 2表示请求成功
200 OK: 请求成功。通常,这个状态码表示请求已经成功。- 201 Created: 请求已经被成功处理,并且服务器创建了新的资源。
- 204 No Content: 请求成功,但响应不包含实体的主体部分,通常用于DELETE请求。
- 3表示重定向,要么告知客户端使用替代位置来访问他们感兴趣的资源,要么是服务器提供一个替代的响应而不是请求资源的内容
- 301 Moved Permanently: 请求的资源已被永久移动到新的位置,将来的请求应使用新的URL。
- 302 Found: 请求的资源临时移动到新的位置,将来的请求仍应使用原始的URL。
304 Not Modified: 表示资源在客户端缓存中仍然有效,可以直接使用缓存的版本。
- 4表示客户端错误,指浏览器发送了服务器无法处理的内容
- 400 Bad Request: 客户端发送的请求有语法错误,服务器无法理解。
401 Unauthorized: 请求未经授权,需要身份验证。- 403 Forbidden: 服务器理解请求,但拒绝执行。通常是因为没有足够的权限。
404 Not Found: 请求的资源不存在。
- 5表示服务端错误
500 Internal Server Error: 服务器遇到了一个未知的错误,无法完成请求。- 501 Not Implemented: 服务器不支持请求的功能,无法完成请求。
502 Bad Gateway: 作为网关或代理服务器的服务器,从上游服务器收到无效的响应。- 503 Service Unavailable: 服务器当前无法处理请求,通常是由于维护或过载。
504 Gateway Timeout: 作为网关或代理服务器的服务器,在规定的时间内未能从上游服务器接收到响应。
还有一些其他不是很常用的状态码,这里没有单独列出了。
由于HTTP是一个在应用程序中直接操作的协议,返回的状态码完全由应用开发者自己控制,因此在某些时候返回的状态码与实际原因可能并不一致,需要结合实际场景分析。
无状态
每个HTTP请求/响应都是一个独立的事务,服务器不会保留先前请求的状态。这使得HTTP协议设计简单,但也带来了一些额外的开销,因为每次请求都需要重新建立连接。
keep-alive
在早期,当一个HTTP请求响应完毕后,就会断开本次TCP连接。如果HTTP请求比较频繁,这种为单个请求建立TCP连接的方式就比较浪费。
可以通过配置Connection:keep-alive和Keep-Alive:timeout=x,max=xx的响应头来改善这种状态。
可以理解为HTTP的 keep-alive是为了让TCP活得更久一点:当一个HTTP相应完毕后,理应立即关闭本次链接,服务端此时会等待timeout秒,然后才关闭这个链接。
由于每个HTTP请求都是独立的,服务器不会保存客户端的状态信息。
为了处理状态,例如用户的登录状态,通常需要使用会话(Session)机制,或者将状态信息通过Cookie等方式保存在客户端。
Cookie
Cookie是服务器发送到用户浏览器并保存在浏览器上的一块数据,它会在浏览器下一次发起请求时被携带并发送到服务器上。
Cookie的使用使得基于无状态的HTTP协议上记录稳定的状态信息成为了可能。
Cookie非常依赖于浏览器,不同浏览器之间的Cookie是不能通用的。可以笼统地将Cookie分为两类:会话Cookie和持久Cookie:
- 会话Cookie是临时Cookie,用户退出浏览器时Cookie就被删除了
- 持久Cookie是指会被保存在硬盘上的Cookie信息,浏览器退出,计算机重启时他们仍然存在。
- 会话Cookie与持久Cookie的区别在于是否为他们设置了过期时间,如果没有,则为会话Cookie。接下来看看服务器是如何在响应报文中设置Cookie的
服务端通过响应报文的Set-Cookie字段设置Cookie
Set-Cookie: <cookie-name>=<cookie-value>; [Domain=<domain-value>;][Secure;][HttpOnly;][Expires=<date>][Max-Age=<non-zero-digit>][Path=<path-value>]需要注意服务端Set-Cookie一些特殊的修饰符
Secure,表示只有在HTTP使用SSL安全连接时才发送该cookieHttpOnly,表示该Cookie无法被客户端Javascript操作
浏览器通过请求报文的Cookie字段发送Cookie
Cookie: name=value; name2=value2; name3=value3在浏览器中可以通过document.cookie来操作cookie。
Session
Cookie将用户身份信息保存在浏览器,并在每次请求时携带对应信息到服务器。此外,也可以直接在服务器保存用户身份,这种方式称为Session。
维持session会话的核心就是客户端的唯一标识,即SessionID,SessionID就像是用户的身份证账号一样,只需要提供值,服务器就会自动检索并查找到用户的身份信息。
传递sessionId一般有下面几种方式
- 最常用的方式是通过Cookie
- 通过URL参数
- 通过表单隐藏字段
服务器使用类似于散列表的结构来保存多个用户的信息,每个用户的信息使用SessionID来索引,这就是SessionID必须唯一且不能被伪造的原因。 用户信息可以保存在内存中,文件中或者数据库中。
在实际应用中,Cookie 和 Session 经常一起使用,Cookie 用于存储一些客户端相关的信息,而 Session 则用于存储敏感或用户身份验证等数据。
HTTP缓存
缓存的好处:
- 减轻了服务器的压力,服务器不必为来自同一个客户端的资源请求进行重复处理
- 提高了客户端的加载速度,从本地或者就近的缓存中读取资源,比从遥远的服务器获取资源要快得多
下面是与缓存相关的一些条件请求头部
if-Modified-Since设置更新时间,从更新时间到服务端接受请求这段时间内如果资源没有改变,允许服务端返回304 Not ModifiedIf-None-Match设置客户端ETag,如果和服务端接受请求生成的ETage相同,允许服务端返回304 Not ModifiedIf-Match设置客户端的ETag,当时客户端ETag和服务器生成的ETag一致才执行,适用于更新自从上次更新之后没有改变的资源If-Range设置客户端ETag,如果和服务端接受请求生成的ETage相同,返回缺失的实体部分;否则返回整个新的实体If-Unmodified-Since设置更新时间,只有从更新时间到服务端接受请求这段时间内实体没有改变,服务端才会发送响应
下面是强缓存和协商缓存的相关流程
@startuml cache
start
:请求资源;
if(浏览器私有缓存) then (Y)
if(新鲜度检测) then(Y)
:200(from cache);
stop
else (N)
if(服务器再验证) then(Y)
:HTTP 304;
:浏览器更新新鲜度;
:304(not modified);
stop
endif
endif
else (N)
:未命中缓存,直接请求资源;
endif
if(资源存在) then(Y)
:新内存存入缓存;
:HTTP 200;
stop
else
:HTTP 404;
stop
@enduml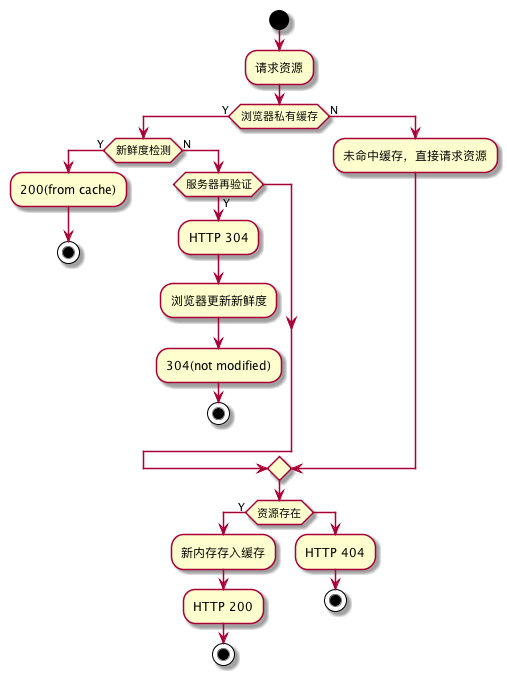
HTTP2
参考
二进制格式传输与多路复用
在HTTP/2中,新增了二进制分帧层,将数据转换成二进制,也就是说HTTP/2中所有的内容都是采用二进制传输
帧是HTTP/2中数据传输的最小单位;每个帧都有stream_ID字段,表示这个帧属于哪个流,接收方把stream_ID相同的所有帧组合到一起就是被传输的内容了。HTTP/2共定义了十种帧,较为常见的有数据帧、头部帧、PING帧、SETTING帧、优先级帧和PUSH_PROMISE帧等,为将来的高级应用打好了基础
在这种多路复用传输模式下,HTTP请求变得十分廉价,我们不需要再时刻顾虑网站的http请求数是否太多、TCP连接数是否太多、是否会产生阻塞等问题了。
HPACK 首部压缩
HTTP/1中,每个请求和响应都会携带对应的头部信息,每个页面的请求越多,越来越多的请求导致消耗在头部的流量越来越多,尤其是每次都要传输 UserAgent、Cookie 这类不会频繁变动的内容,完全是一种浪费
为了减少冗余的头部信息带来的消耗,HTTP/2采用HPACK 算法压缩请求和响应的header。其具体原理为
- 通信双方共同维护了一份静态表,包含了常见的头部名称与值的组合(比如method:GET,可以存在表中,然后只需要传递一个键名即可)
- 根据先入先出的原则,维护一份可动态添加内容的动态表
- 用基于该静态哈夫曼码表的哈夫曼编码数据
这样可以极大地节省头部的消耗
server push
HTTP/2的server push允许服务器在未收到请求时主动向浏览器推送资源。这样可以将资源提前推送到到浏览器:除了静态文件,还可以推送比较耗时的API
在HTTP1.1时代,也有提前获取资源的方法,如preload和prefetch,
- preload是在页面解析初期就告诉浏览器,这个资源是浏览器马上要用到的,可以立刻发送对资源的请求,当需要用到该资源时就可以直接用而不用等待请求和响应的返回了
- prefetch是当前页面用不到但下一页面可能会用到的资源,优先级较低,只有当浏览器空闲时才会请求prefetch标记的资源。
从应用层面上看,preload和server push并没有什么区别,但是server push减少浏览器请求的时间,略优于preload,在一些场景中,可以将两者结合使用。